When we say SEO, people usually think about outreaching for backlinks or stuffing keywords into your content. It’s actually more than that.
Hunting for links is something we know as Off-page SEO while we call the on-site tasks as On-page SEO.
Another major aspect that many people aren’t really aware off is technical SEO.
Technical SEO mainly refers to those tech-savvy tasks which are focused on how well the search engines can crawl your website pages and index your content.
You probably have come across terms like robots.txt, XML sitemap, Page speed optimization, tags and so on. Most of the SEO’s probably have done it at some point.
But most of them do not really consider all these technical stuff as a phenomenon of SEO. While I and many other industry experts take these as an aspect itself of SEO.
In these world of enhanced CMS’s like WordPress, Joomla and such, things are so-already-set-up that you don’t feel the depth of this aspect. But at the end of the day, CMS’s are also built out of codes and so are search engine bots and algorithms.
So you just can relax out too much here, rather dedicate a part of your attention on the technical aspect of your website to ensure that it has a smooth mechanism to run the bridge that connects your site with search engines.
Table of Contents
What Can Happen if Technical SEO isn’t Done Right?

To emphasize technical SEO’s important even more, let me tell you that if there’s noticeable error in it, you could put a whole world of efforts behind a content to make it awesome and another world to market it and gather links, but it won’t rank. (How would it, if it ain’t even indexed properly, means Google doesn’t even know about this!)
Worst case scenario, you’ll get kicked in the ass by Google (Google Penalty) as many people got a few days back.

They couldn’t handle technical things properly and their images in the content were getting indexed separately which google ultimately considered as thin content and penalized them.
This incident happened due to an issue of a popular WordPress SEO plugin though! (let me not disclose the name since it’s really popular and I might face legal issues)
Now that said, the people having the knowledge of technical SEO, could save their ass this time since they could detect the error because of their knowledge in it.
So it’s a better practice to learn at least the basics of this aspect and not blindly rely on a plugin that could ruin your whole website.
And trust me, Technical SEO is an awesome field and when you’re into it, you’re gonna enjoy it!
Don’t trust me? Let me demonstrate!
Technical SEO Facts That You Should Know as an SEO
#Page Speed is Critical
Page speed is the most highlighted aspect of technical SEO that has a direct correlation with ranking.
If your page or website loads slow, it’s very less likely to rank even if you have hundreds of links pointing towards your site.
Also, your audience would love a faster loading site and hate a site that loads slow, and most likely to hit the back button.

A study says, 40% of visitors hit the back button if the page takes more than 3 seconds to load. The same study states that visitors have 60% more page views and spend 70% more time on a website that load quickly. [Source]
So it’s crucial for both rankings in the search engine and visitor’s experience with your site.
Google has their own PageSpeed Insights tool that gives you an overview of your website’s current loading time and also suggests what’s wrong.
They also have this new page speed tool out which is a mobile-focused page speed tool.
This tool checks the load time of your pages from a mobile device, evaluate mobile usability, test your mobile site on a 3G or 4G connection, and does many more.
#robots.txt file is case-sensitive and obsolete if not kept in the main directory
Make sure you name the ‘robot’ file just the way I did – ‘robots.txt’.
Robots.txt?, ROBOTS.txt? Obsolete, not going to work. All the characters must be in lower case for search engines to recognize it.

Another way you can make it obsolete is keeping it in another directory of the site, but not the main one. Which I think, you don’t wanna do.
Search engine crawler looks for a robots.txt file only in the site’s main directory. If they don’t find it there, they assume there is no such file and oftentimes simply continue to crawl.
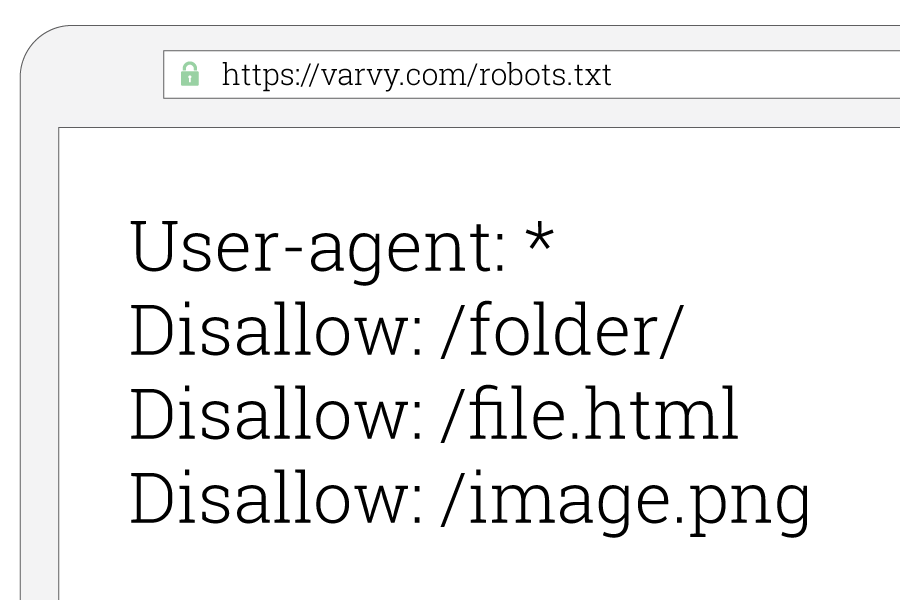
So make sure you name the robots.txt file right and put it in the right place which is the main directory of your site.
Infinite Scroll is not always accessible for Crawlers
Which you don’t want to happen, because if crawlers can’t access it, the page may not rank.
You want to make sure that there is a paginated series of pages in addition to the one long scroll when you’re using infinite scroll for your site.
You also need to implement replaceState/pushState on the infinite scroll page. This fun little optimization hasn’t come into the light of many web developers, so make sure to check your infinite scroll for rel=”next” and rel=”prev“ in the code.
Sitemap Structure Doesn’t Matter

Do not stress much over your sitemap structure as Google does not care about it. The overall structure and category breakdown of the sitemap is completely up to you and do it in the way you like as long as it’s XML.
You have the freedom to structure your sitemap as you’d like, without worrying about how Google will crawl it.
There are Some Other facts to Know About Sitemaps
- You need to make sure that XML sitemaps are UTF-8 encoded.
- They are not supposed to include session IDs from URLs.
- The URL limit for sitemaps is 50k, and they must not be larger than 50 megabytes (MB)
- You have the liberty to use different sitemaps for different media types like Images, News, Videos and other types.
Google let you check how their mobile crawler is seeing your web pages
According to statista, mobile devices accounted for a massive 49.7 percent of web page views worldwide (As of February 2017). Also, mobile internet traffic stands at 51.2 percent of total online traffic worldwide.
That said, it’s not difficult to understand why Google has migrated to mobile-first index. And that makes it a must-do job for website owners to make sure their pages perform well on mobile devices like smartphones and tabs.
The good thing is, Google themselves offer a tool themselves known as Mobile Usability that tells you how well your pages are actually performing on mobile devices, which is much more in-depth than just checking your website from your smartphone.

The tool shows if any of your pages in your whole website has an issue with mobile devices. There’s another tool named mobile-friendly test that provides you other insights as well.
An ‘S’ Matters Even Big Time Now With Chrome’s Update
An ‘s’ in the address bar that differentiates ‘https’ and ‘HTTP’ now have a more significant effect than ever.
This ‘s’ indicates whether a website is SSL certified or not. SSL certified shows ‘https’ in the address bar whereas not certified shows only as ‘HTTP’, no ‘s’.

SSL ensures more secure connection to clients and servers so sensitive data pass on being encrypted and more secured.
Since Google cares a lot about privacy and security, they’ve designed their latest update of vastly used ‘Chrome’ browser to flag non-SSL certified browsers as ‘Not secure’, even when you’ve not entered the website, just entering the URL.
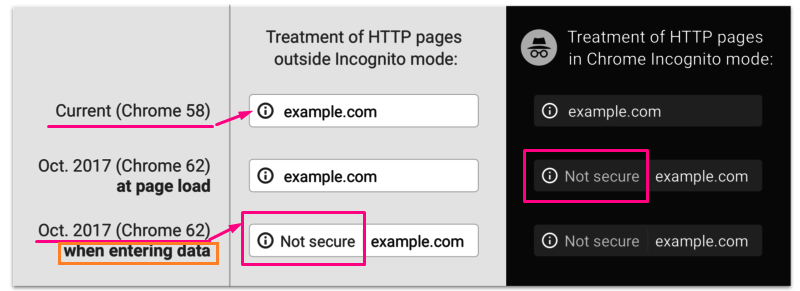
This creates a lack of trust for your website in the visitors’ mind right off the bat and you might end up losing a lot of visits.
Apart from that, Google tends to give a ranking boosts to secured sites as well, as we can understand from Moz’s report that says ‘over half of the websites on the first page of google search results are HTTPS’.
So it shows that google tends to rank the websites having an ‘s’ after ‘http’, so an ‘s’ matters, big time!
Disallow directives in the robots.txt file does not always stop Google to index your website pages
We all use the “Disallow” directive in your robots.txt file when we don’t want Google to crawl particular web pages as we don’t want those pages to index.

This is what ‘disallow’ directive robot.txt in file is all about – simply telling Google not to crawl the disallowed pages/folders/parameters specified.
Well, Google listens to us and do not crawl those web pages, but that does not always mean these pages won’t be indexed.
As stated in Google’s Search Console Help documentation, they tell us not to use robots.txt as a means to hide our web pages from Google Search results, as it will not always work this way.
Because, there might be other pages pointing to that particular page that we prohibited Google from crawling, but it could still get indexed because of this reason, avoiding the robots.txt file.
They recommend using other methods like password protection or noindex tags or directives if we want to block any of our particular pages from search results.
So if you really want Google to stop any of your webpages, you should look forward to obtaining other ways than just using the disallow tag on your robots.txt file.
Noarchive tags are meant to tell Google not to show the cached version of a page in its search results. Many have the misconception that it affects the ranking of that page thus get afraid of using it.

To bust the myth, it does not negatively affect the overall ranking of that particular page. Next time when you need to use the tag, use it with confidence.
Home Page Usually Comes First
It’s not a hard and fast rule that Google will always crawl your homepage first, but it’s the scenario that’s most likely to happen.
See what John from Google has to tell about it –
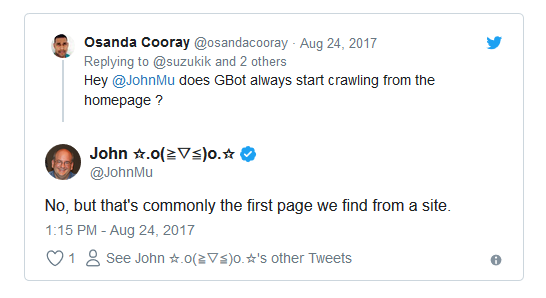
An exception could happen if there’s any particular page in your site that has a huge number of links pointing towards it. In such case, it’s likely to get the attention first.
Crawl Budget Fact
Crawl budget indicates the number of pages that search engines have the ability and wish to crawl in a given amount of time. You can get an overview of crawl budget for your site in your Search Console.
You get the chance to increase it as well.
There are often pages in your site that are not essential to your SEO efforts like privacy policies, terms and condition pages, expired promotions etc.
These are pages that are not meant to rank, and often does not have fully unique content. Block these pages to allocate your crawl budget better.
Keep Redirects in Place for a Year at least
John Muller from Google Switzerland recommends keeping 301 redirects live and in place for 12 months at least. That’s because it can take several months for Google to identify that a website has been moved.

The best practice is to never getting rid of redirects for important pages with rankings, links, and good authority.
That’s all for Fun Technical SEO Facts
For today I had these 12 fun technical SEO facts to share with you. There are much more of it, but these are the critical few fun ones to chew on.
There’ll probably be more of it – more fun technical SEO facts in the coming days. Stay tuned.

